Programming
An Exposition on CuPy Math Libraries
GPU-Accelerated Paradigms for High-Performance Scientific Computation
4. 2. 2025

Abstract
The contemporary landscape of scientific computation is undergoing a paradigm shift with the advent of heterogeneous computing architectures that harness the immense parallelism of graphics processing units (GPUs). Among the myriad libraries developed to exploit these architectures, CuPy has emerged as a compelling Python-based framework that offers a near drop-in replacement for NumPy, while delivering substantial performance enhancements for mathematically intensive operations. This article provides a deep and rigorous exploration of the CuPy math libraries, focusing on their architectural nuances, advanced algorithmic integrations, and the interplay between numerical precision and performance. Through detailed discussions on linear algebra, Fourier transforms, random number generation, and custom kernel implementations, we elucidate how CuPy leverages low-level CUDA libraries such as cuBLAS, cuFFT, and cuSOLVER to accelerate high-performance computations.
1. Introduction
In scientific computing, the efficient evaluation of mathematical operations is paramount. Traditionally, central libraries such as NumPy have been the de facto standard for array-based computations in Python. However, the emergence of GPU-accelerated libraries like CuPy has revolutionized this field by allowing researchers and engineers to overcome the bottlenecks associated with serial CPU processing. CuPy provides a Pythonic interface that mirrors NumPy’s API while seamlessly integrating with NVIDIA’s CUDA ecosystem to harness the computational power of GPUs.
This treatise endeavors to deliver an intellectually rigorous analysis of CuPy’s math libraries. We dissect the underlying architecture, examine the theoretical and practical challenges of implementing advanced mathematical operations on GPU hardware, and highlight the strategies used to mitigate issues related to memory management, numerical stability, and algorithmic efficiency.
2. Background and Motivation
2.1 The Evolution of Numerical Computing
The advent of GPU computing has necessitated a fundamental rethinking of algorithm design and resource management. Historically, numerical operations have been optimized for CPU architectures, which excel in sequential processing but lag behind GPUs in terms of parallel throughput. The shift to GPU computing entails not only a change in hardware but also the adoption of paradigms that leverage massive parallelism. In this context, CuPy stands out as a library that abstracts away many of the complexities of GPU programming while providing a robust set of mathematical functionalities.
2.2 CuPy in the Context of Heterogeneous Computing
CuPy’s design is predicated on the need for an interface that allows seamless migration from CPU-based NumPy code to GPU-accelerated computations. The library achieves this by emulating the NumPy API closely, ensuring that legacy code can be adapted with minimal modifications. However, beneath this familiar facade lies a sophisticated architecture that orchestrates low-level CUDA calls, manages memory pools, and executes highly optimized kernels that are tailored to exploit GPU parallelism.
3. Architectural Overview of CuPy Math Libraries
The CuPy library is modular in nature, comprising several submodules dedicated to specific classes of mathematical operations. Key among these are:
cupy.ndarray: The fundamental data structure, analogous to NumPy’s ndarray, but allocated on the GPU.cupy.linalg: A module that implements linear algebra operations such as matrix multiplication, eigenvalue decomposition, and singular value decomposition (SVD).cupy.fft: Provides fast Fourier transform routines that interface with cuFFT, enabling efficient spectral analysis.cupy.random: Implements pseudo-random number generation using CUDA’s capabilities.cupy.cuda: Contains low-level interfaces for memory management, kernel compilation, and stream synchronization.
Each of these submodules encapsulates advanced algorithmic strategies that not only parallelize computation but also address the intricacies of GPU memory hierarchy and latency.
4. Deep Dive into CuPy Mathematical Submodules
4.1 Linear Algebra: cupy.linalg
The cupy.linalg module is a cornerstone for scientific applications that rely on linear algebra. It offers a wide array of functions including, but not limited to, matrix inversion, determinant computation, eigenvalue decomposition, and solving linear systems.
4.1.1 Integration with cuBLAS and cuSOLVER
At the heart of these operations lies an intricate coupling with CUDA’s highly optimized libraries:
cuBLAS (CUDA Basic Linear Algebra Subprograms):
CuPy delegates many matrix and vector operations to cuBLAS routines, ensuring that operations like matrix multiplication (GEMM), vector dot products, and batched operations are executed with optimal throughput.cuSOLVER:
More complex operations such as Cholesky decomposition, LU decomposition, and singular value decomposition are routed through cuSOLVER. This library provides robust, numerically stable algorithms that are crucial for applications requiring high precision.
For instance, the matrix multiplication of two arrays AAA and BBB in CuPy can be abstractly represented as:
C=AB,C = AB,C=AB,
where CCC is computed using highly parallelized kernels that minimize memory latency. The performance gain here is not merely a factor of parallelism but also a consequence of minimizing data transfer overheads between the host (CPU) and device (GPU).
4.1.2 Numerical Stability and Precision Considerations
While GPUs offer impressive raw throughput, ensuring numerical stability is nontrivial. Floating-point arithmetic on GPUs can be susceptible to rounding errors, especially in iterative algorithms. CuPy mitigates these issues by supporting both single (float32) and double (float64) precision modes. However, the choice between them is often a trade-off between speed and accuracy. Advanced users can explicitly control precision to optimize the balance between computational efficiency and the tolerable error margins in their applications.
4.2 Fast Fourier Transforms: cupy.fft
The cupy.fft module leverages NVIDIA’s cuFFT library to perform fast Fourier transforms (FFTs) on GPU-resident data. FFTs are indispensable in various domains ranging from signal processing to solving partial differential equations (PDEs) in the spectral domain.
4.2.1 Theoretical Underpinnings
The discrete Fourier transform (DFT) of a sequence xnx_nxn is defined as:
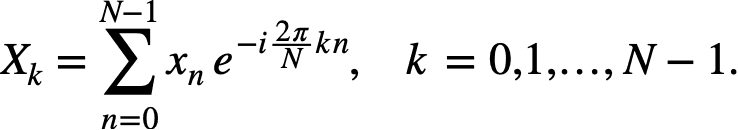
The cuFFT library optimizes this computation by exploiting the Cooley-Tukey algorithm, which reduces the computational complexity from
CuPy abstracts this complexity, allowing users to compute FFTs with a syntax analogous to NumPy’s fft module.
4.2.2 Practical Implications
The acceleration of FFTs on GPUs is particularly significant in real-time data processing and large-scale simulations. CuPy’s FFT routines ensure that even high-dimensional transforms are executed efficiently, making it a vital tool for researchers in computational physics, engineering, and applied mathematics.
4.3 Random Number Generation: cupy.random
Statistical modeling, Monte Carlo simulations, and various stochastic methods hinge on the generation of high-quality random numbers. The cupy.random module addresses this by providing a suite of pseudo-random number generators (PRNGs) that operate directly on the GPU.
4.3.1 Algorithmic Considerations
CuPy’s random module is built upon CUDA’s parallel random number generation libraries, such as cuRAND. The design ensures that random variates can be generated concurrently, thus mitigating the serial bottlenecks typically associated with CPU-based random number generation. The algorithms employed must guarantee statistical independence and uniformity across parallel streams—a nontrivial challenge given the inherent parallelism of GPU architectures.
4.3.2 Applications in Scientific Computing
Efficient random number generation is critical in Monte Carlo integration, stochastic differential equations, and various probabilistic algorithms. By offloading these tasks to the GPU, CuPy enables significant reductions in computation time, thereby accelerating simulations that would otherwise be constrained by CPU performance.
4.4 Custom Kernel Generation and the cupy.cuda Module
One of CuPy’s most powerful features is its support for custom kernel generation via the cupy.cuda module. This capability allows users to write raw CUDA kernels in C-like syntax, which are then compiled at runtime using the NVIDIA Runtime Compilation (NVRTC) framework.
4.4.1 Kernel Fusion and Optimization
Kernel fusion is an optimization technique that amalgamates multiple elementwise operations into a single kernel launch, thereby reducing the overhead associated with kernel invocation. In CuPy, the ElementwiseKernel and ReductionKernel constructs allow for the creation of highly optimized routines that are tailored to specific computational patterns. Consider, for example, the following pseudo-code for an elementwise operation:
This example illustrates the ease with which domain-specific kernels can be developed, facilitating the implementation of custom mathematical operations that can run entirely on the GPU. For more Please visit our technical Docs
4.4.2 Synchronization and Stream Management
Managing asynchronous execution and stream synchronization is crucial for maximizing throughput while ensuring computational correctness. CuPy’s low-level CUDA interfaces provide mechanisms for stream creation and event handling, thereby enabling fine-grained control over the execution order of kernels. This is particularly important when dependencies exist between operations, as improper synchronization can lead to race conditions and erroneous results.
5. Memory Management and Performance Considerations
5.1 GPU Memory Hierarchy and Allocation Strategies
The performance of GPU-accelerated operations is heavily dependent on effective memory management. CuPy employs a caching memory pool to mitigate the latency associated with frequent memory allocations and deallocations on the GPU. This pool-based strategy reduces overhead by recycling memory blocks, thereby maintaining high throughput in iterative computations.
5.2 Minimizing Data Transfer Overheads
Data transfer between the host (CPU) and device (GPU) is a notorious bottleneck in heterogeneous computing. CuPy’s design philosophy advocates for minimizing such transfers by keeping data resident on the GPU for as long as possible. By doing so, the library leverages the high-bandwidth memory available on modern GPUs, ensuring that operations such as large-scale matrix multiplications and FFTs are not impeded by the relatively slower PCIe interface.
5.3 Balancing Precision and Performance
The choice between single and double precision is often dictated by the application’s tolerance for numerical error. In many high-performance scenarios, single precision (float32) is preferred due to its lower memory footprint and faster arithmetic operations. However, for applications demanding high numerical fidelity—such as iterative solvers in computational fluid dynamics or financial modeling—double precision (float64) may be indispensable. CuPy provides users the flexibility to select the appropriate precision mode, but it also necessitates a careful analysis of the trade-offs involved.
6. Theoretical Underpinnings and Algorithmic Complexity
6.1 Parallel Algorithm Design
Designing algorithms for GPUs is fundamentally different from CPU-based approaches. GPUs excel at executing the same instruction across a vast array of data points (SIMD: Single Instruction, Multiple Data), making them ideal for data-parallel tasks. Many of the mathematical operations in CuPy are thus formulated to exploit this parallelism. For example, consider the parallel reduction algorithm used to compute the sum of an array. While a naive implementation on a CPU might involve a loop over all elements, a GPU implementation divides the array into segments, each processed concurrently, and then iteratively reduces the partial sums.
6.2 Complexity Analysis in a Heterogeneous Context
The theoretical complexity of an algorithm must be reinterpreted in the context of GPU computing. Although an algorithm may have a complexity of O(NlogN)\mathcal{O}(N \log N)O(NlogN) in theory, factors such as memory latency, bandwidth limitations, and kernel launch overhead can alter the practical performance. In CuPy, the seamless integration with optimized CUDA libraries helps mitigate these challenges, but a deep understanding of both the algorithm and the underlying hardware is essential for pushing the performance envelope.
7. Comparative Analysis: CuPy Versus Traditional Libraries
7.1 CuPy and NumPy: A Symbiotic Relationship
CuPy is often heralded as a drop-in replacement for NumPy, yet it represents a significant evolution in computational strategy. Whereas NumPy is limited by CPU performance and memory architecture, CuPy exploits the parallelism of GPUs. Comparative benchmarks typically reveal speed-ups ranging from one to several orders of magnitude for operations that are highly parallelizable.
7.2 Beyond CuPy: Other GPU-Accelerated Libraries
While CuPy is a leader in GPU-accelerated array operations in Python, it operates within a broader ecosystem that includes libraries such as TensorFlow, PyTorch, and RAPIDS. Unlike deep learning frameworks that are optimized for neural network computations, CuPy’s design is more general-purpose, catering to a wide array of mathematical operations across scientific domains. Its versatility and close adherence to the NumPy API make it uniquely suited for researchers who require both flexibility and high performance.
8. Applications and Use Cases
8.1 Computational Physics and Engineering
In fields such as computational fluid dynamics, structural analysis, and electromagnetics, the ability to solve large systems of linear equations or perform spectral analysis in real time is crucial. CuPy’s math libraries, particularly its linear algebra and FFT modules, have been successfully applied in simulations that demand both high precision and rapid execution.
8.2 Data Science and Machine Learning
Although primarily associated with deep learning frameworks, many machine learning algorithms benefit from the acceleration provided by CuPy. From principal component analysis (PCA) to clustering algorithms, the ability to perform matrix operations at scale has a direct impact on the training and evaluation phases of machine learning pipelines.
8.3 Financial Modeling and Risk Analysis
In quantitative finance, Monte Carlo simulations and stochastic modeling are computationally intensive tasks. By offloading random number generation and matrix computations to the GPU, CuPy enables financial analysts to run more simulations in a shorter period, thereby refining risk models and portfolio optimizations.
9. Limitations and Future Directions
9.1 Current Limitations
Despite its many advantages, CuPy is not without its challenges:
Memory Constraints: GPU memory is inherently limited compared to system RAM, which can restrict the size of datasets that can be processed.
Precision Trade-Offs: The choice between single and double precision remains a critical trade-off, particularly for applications requiring high numerical accuracy.
Debugging Complexity: Debugging GPU code, especially custom kernels, can be significantly more challenging than debugging standard CPU code due to the asynchronous and parallel nature of execution.
9.2 Prospective Enhancements
The future of CuPy lies in continuous integration with emerging CUDA features and hardware improvements. Potential areas for advancement include:
Enhanced Multi-GPU Support: Facilitating seamless parallelism across multiple GPUs to further scale performance.
Automated Kernel Optimization: Leveraging machine learning techniques to automatically tune kernel parameters for optimal performance.
Expanded API Coverage: Incorporating a broader range of mathematical functions and statistical distributions to cater to an even wider array of scientific applications.
10. Conclusion
CuPy represents a significant milestone in the evolution of numerical computing, bridging the gap between the high-level, user-friendly interfaces of Python and the raw computational power of GPUs. Its math libraries—spanning linear algebra, Fourier transforms, random number generation, and custom kernel execution—demonstrate the profound impact that optimized, parallelized computation can have on scientific and engineering disciplines.
By harnessing the capabilities of underlying CUDA libraries such as cuBLAS, cuFFT, and cuSOLVER, CuPy not only accelerates computations but also fosters an environment in which complex mathematical operations can be performed with both speed and precision. As GPU architectures continue to evolve and new computational paradigms emerge, CuPy is poised to remain at the forefront of high-performance scientific computing, offering a robust and flexible toolkit for tackling some of the most challenging computational problems of our time.
References
NVIDIA cuBLAS Library: https://developer.nvidia.com/cublas
NVIDIA cuFFT Library: https://developer.nvidia.com/cufft
NVIDIA cuSOLVER Library: https://developer.nvidia.com/cusolver
CUDA Programming Guide: https://docs.nvidia.com/cuda
CuPy Official Documentation: https://docs.cupy.dev
Digital Trans4orMation: https://trans4mation-bs.com/cs/introdcution_to_docs/math-library-template-cupy
In summary, CuPy’s math libraries serve as a testament to the power of GPU acceleration in modern scientific computation. Through a confluence of advanced algorithm design, efficient memory management, and seamless integration with CUDA’s suite of libraries, CuPy not only addresses the computational demands of today’s applications but also lays a robust foundation for the innovations of tomorrow.
written by Matthew Drabek
For our Services, feel free to reach out to us via meeting…
Please share our content for further education